
Project Background
For better performance, business has the need to understand how the content are related to each other among emojis, hashtags and mentions in social media. Therefore Machine Learning is used for the analysis of similarity and dissimilarity.
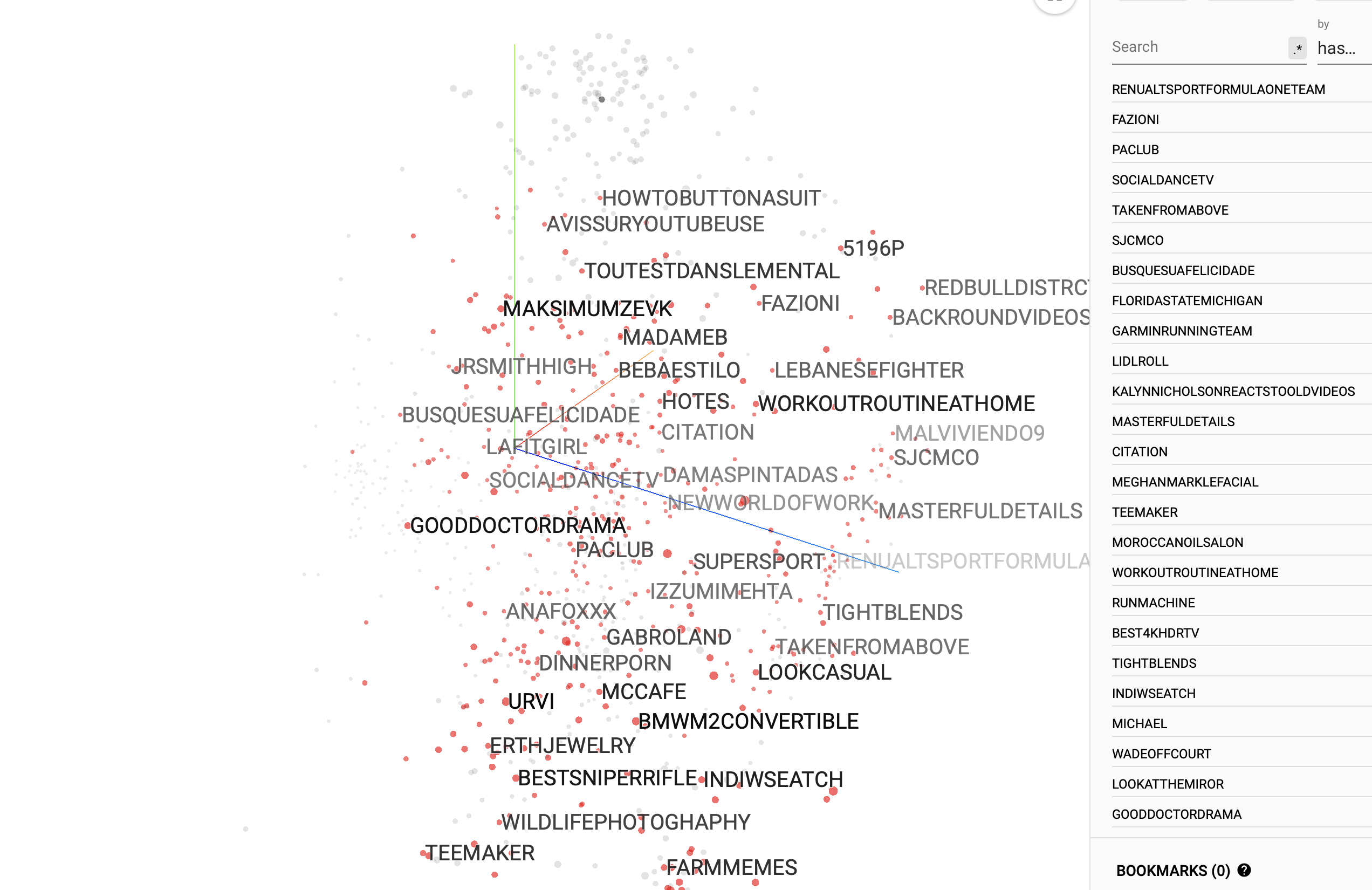

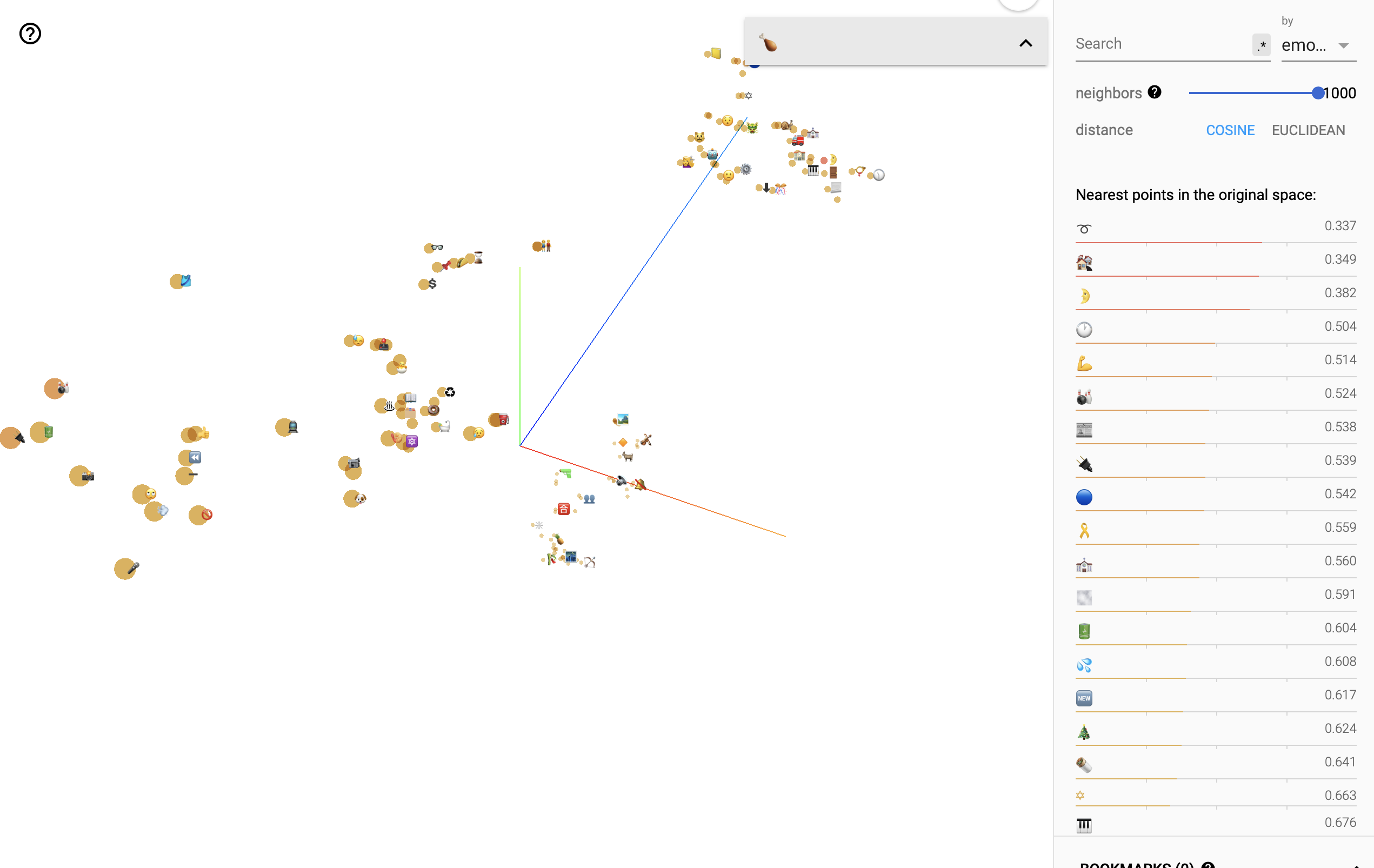
Challenges & Requirements
To ensure a thorough analysis, it is essential to examine the content based on different categories. This analysis can be made even more insightful by utilizing customized metrics such as the engagement index, which measures how attractive the content is to the audience. Other important metrics to consider include the number of followers the post owner has, the comments received on the post, and the number of likes it has garnered. By clustering the data points into distinct groups, we can identify similarities within each group and distinguish them from other groups, enabling a comprehensive understanding of the data.
- Data need to be clean and metrics have to be calculated before putting into ML model.
- AWS ML instances have to be set up and Python Notebook is used for code running.
- The presentation of the outcomes through visual representation.
Actions & Outcomes
The K-means clustering algorithm is widely recognized as a fundamental unsupervised machine learning technique. By following a series of steps, we are able to generate accurate and insightful results.
- The extraction of source data from BigQuery into tfrecord files serves the crucial purpose of transforming it into cluster data mode.
- The files are classified and then uploaded into AWS S3, after which they are imported into a Python-written model.
- Jupyter Notebooks are executed within AWS to utilize the cloud ML instances.
- The presentation of the outcomes through visual representation.
The results imply that certain components of the content have a propensity to group together and display similarities.
Incredible developer. I ran late on the information at times but communicated very well and followed up everything perfectly. Amazing developer! 5 stars is not enough!!!
Technologies Used
The data is extracted from BigQuery and transformed into TFRecord format. The K-Means Cluster algorithm is orchestrated using Tensorflow in Python. The model is executed using AWS Jupyter notebook.
Conclusions
By gaining a deeper comprehension of the similarities between content components, we can enhance the performance of our posts by connecting them to similar elements, thereby creating a cohesive narrative. Additionally, we can expand our reach by engaging with distant content components to attract new audiences. As this field is relatively unexplored, it may be necessary to conduct further research and analyze larger data sets in order to validate these findings.



