
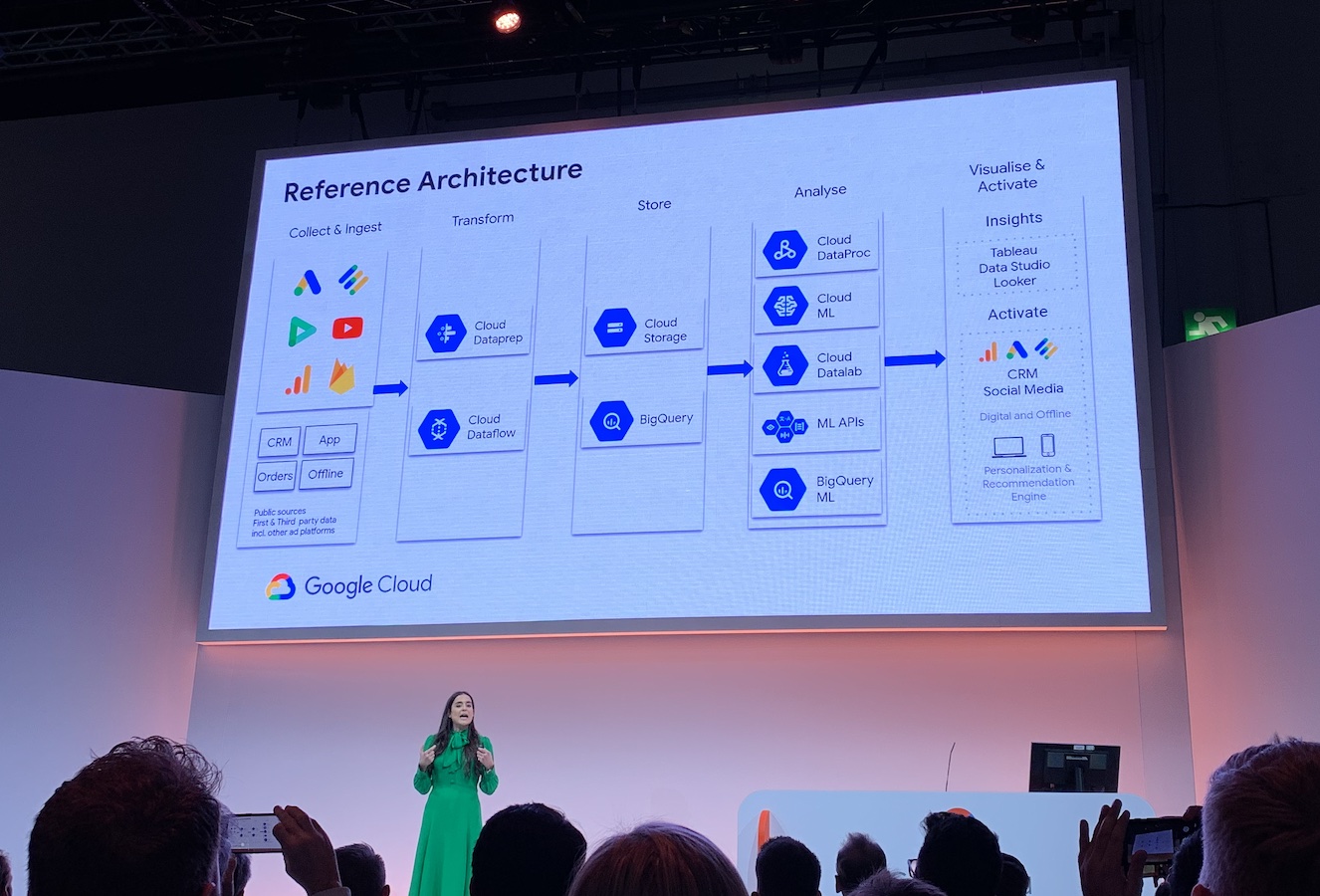
Project Background
To ensure effective analysis, it is necessary to aggregate and transform both incoming and existing data within the BigQuery tables. Apart from batch processing, a streaming and long running data pipeline has been established. Given the vast amount of data from 20K brands across various social media platforms, an auto scalable cloud architecture is essential, along with a disaster recovery mechanism. Furthermore, the system should be adaptable to accommodate future data features from constantly evolving data sources.
Challenges & Requirements
The objective of this project is to dynamically convert data in order to highlight and extract real-time streaming data insights. Once the data has been transformed, it is stored in the Google BigQuery data warehouse. Batch processing tasks were utilized to fulfill ad-hoc requirements.
- In order to evaluate performance, it is necessary to compare it with the average metrics, commonly known as benchmarks. To calculate this, a fixed window of 28 days must be established, and the data within this time frame should be stored in memory or in Redis. This allows for the comparison and updating of benchmarks whenever a new post, tweet, or picture is received. The challenge lies in synchronizing these benchmarks across multiple servers and ensuring their timely refreshment. Additionally, the occasional disruptions caused by restarting servers in cloud environments must be considered.
- Numerous posts and tweets contain images that have an expiration date or become invalid over time. Therefore, it is necessary for the system to download these attachments offline in order to showcase the brand's performance in a more persistent manner. This process should be concurrent and non-blocking to ensure the smooth running of the pipeline, with retry logic implemented.
- One of the requirements for data analytics is to have access to external links, which can be achieved by extending the shortened URLs to their original raw URLs. This capability provides valuable insights into the number and identity of external parties referenced. However, a challenge arises in determining the timeout value, as the process may get stuck while parsing and checking the validity of the URLs.
- To handle incoming data efficiently, a buffer layer is essential to prevent excessive delays in data arrival. This buffer layer acts as a temporary data store, waiting to be processed. The digestion process may involve multiple channels for the same data, requiring the data to be replayed at certain intervals and multiple times. This is particularly useful for UAT environments or other business objectives and algorithms.
- The data consists of tens of thousands of keywords, and it is crucial to detect mentions of these keywords in real-time. Whenever a keyword is mentioned in a post, the system should establish the relevant associations.
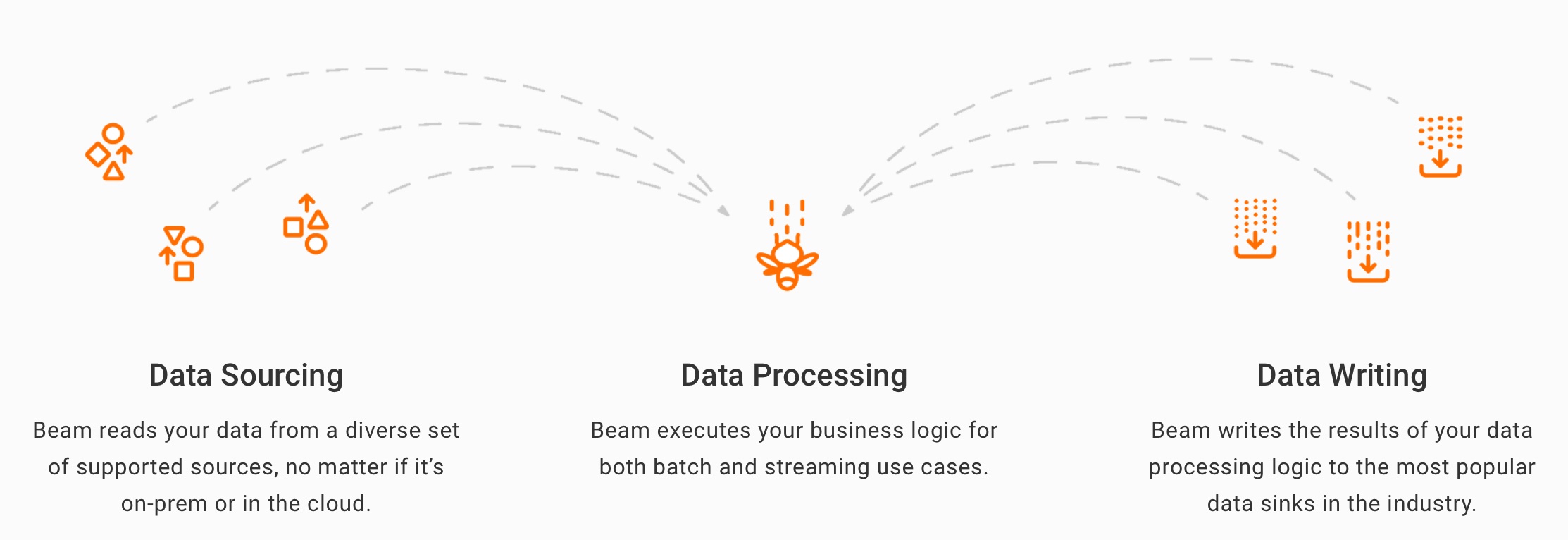
Apache Beam offers a comprehensive solution for data ETL, providing a single platform to handle all your data processing needs. One-time batch processing was utilized for ad-hoc tasks.
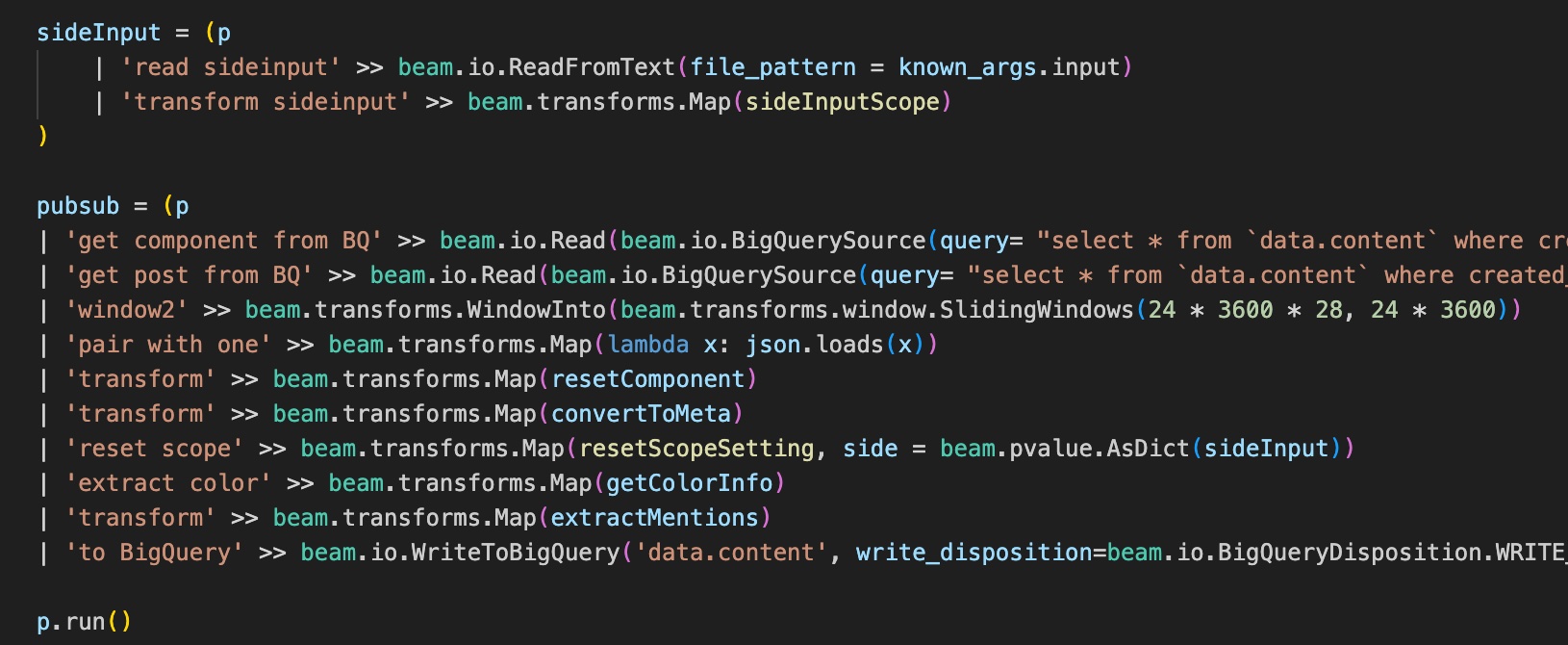
The Python batch codebase demo provided below showcases the utilization of BigQuery as both the data source and data destination.
Actions & Outcomes
After considerting above factors, Google Dataflow is chosen as the infrastucture of data pipeline, PubSub as the incoming data buffer layer.
- Sideinput in Dataflow is used to working on the fixed 28 days time window. The data is read at the initial loading everytime the pipeline gets started.
- Stateful function helped to keep data in the running window, so that the state while doing calculation is perserved and renewed on the fly.
- Google PubSub has the features to replay historical data, and to reproduce the same data for multiple downstream channels. In case of bugs or disruptions, the data can be replayed so that missing gap is prevented.
- FailSafe (net.jodah.failsafe ) library was used as re-try logic.
- Historical data is read as Side input to hold the keywords to be matched against the incoming posts.
Here's a demonstration of the Python batch codebase, showcasing BigQuery as both the data source and data destination.
I highly recommend zhu1230 (Vincent)! My experience with him on my second project has confirmed that he is a consummate professional - he is very responsive and receptive to feedback, fully committed to delivering a great outcome / product and has a quick turnaround time.
Technologies Used
The Java language was utilized to develop the Streaming Dataflow pipeline, leveraging the Apache Beam framework. On the other hand, the Batch processing code was implemented in Python. Both components have undergone thorough testing to ensure the functionality of their core features. BigQuery serves as both the data source and destination for this pipeline. Additionally, the Pub/Sub messaging system is employed as an intermediate stage for streaming data.
Conclusions
The consolidation of the data ETL pipeline has resulted in significant cost reduction, simplification, and streamlined management of various components through the creation of a single, visualizable pipeline. This new design not only replaced multiple sub-projects but also automated the manual scaling up of work on servers, optimizing resource utilization. When combined with Python batch processing, it enhances the process by reducing errors and providing greater flexibility and adaptability to meet business requirements.



